【Linux】ブートローダー
ハードディスクなどのストレージからOSを読み込んで起動するプログラムのこと。
代表的なLinuxのブートローダーとして「GRUB」(グラブ)があり2種類のヴァージョンがある。
インストール
grub-install /dev/sda
※ sdaはディスクドライブインターフェースを表す命名規則。
※ /dev/sdaはシステム上の最初の物理ディスクドライブを指す。
GRUB Legacy 設定ファイル
以下ファイルを編集し設定を行う
/boot/grub/menu.lst
※ディストリビューションによっては「/boot/grub/grub.conf」
GRUB 2 設定ファイル
/etc/default/grub
または
/etc/default/grub.d ディレクトリ内のファイル
上記で設定を行い 下記コマンドの実行で設定を行う
grub-mkconfig
設定に基づいてgrub.cfgファイルが生成される
/boot/grub/grub.cfg
GRUB2コマンド
| 起動オプション | 説明 |
|---|---|
| menuentry | メニューに表示するエントリ名を指定 |
| insmod | GRUB2で用意されているモジュールを使用する際にロードするモジュールを指定 |
| set | 設定項目を指定 |
Linuxカーネル起動オプション
| 起動オプション | 説明 |
|---|---|
| init=<パス> | initの代わりに指定コマンドを実行 |
| root<デバイス名> | ルートパーティションを設定 |
| 数字(0-6) | 指定したランレベルで起動 |
| quiet | 起動中のカーネルからの情報出力を抑制する |
MBR(マスターブートレコード)とは?
HHDなどの外部ストレージの先頭にある起動に必要なプログラムや情報を記録した領域。512バイト。
GRUBなどのブートローダーもこの領域に格納され、446バイトと決まっている。
パーティション
【Linux】rootディレクトリ配下の主なディレクトリの役割
/bin (binary):
主要なシステムコマンドが格納。 通常、システムの基本的な動作に必要なコマンドがここに含まれる。
/boot:
システムのブートローダーとカーネルが格納。 ブートプロセスの初期段階で使用。
/dev (device):
デバイスファイルが格納。 デバイスファイルは、ハードウェアデバイスと通信するための特別なファイル。
/etc (et cetera):
システムの設定ファイルが格納。 ネットワーク構成、ユーザーアカウント、サービスの設定などが含まれる。
/home:
一般ユーザーのホームディレクトリ。 通常、各ユーザーはこのディレクトリ以下に自分専用のサブディレクトリを持つ。
/lib (library):
システムが実行中に使用する共有ライブラリが格納。これらは、プログラムが実行される際に必要な機能を提供。
/media:
取り外し可能なメディア(USBドライブ、CD-ROMなど)がマウントされる場所。
/mnt (mount):
一時的に他のファイルシステムをマウントするためのディレクトリ。
/opt (optional):
オプションのアプリケーションやパッケージがインストールされる場所。
/proc (process):
カーネルやプロセスに関する仮想ファイルが格納。ランタイムで情報を取得可能。
/root:
ルートユーザー(スーパーユーザー)のホームディレクトリ。
/sbin (system binary):
システム管理用のバイナリが格納。通常、ルートユーザーが使用。
/srv (service):
サービスがデータを配置するためのディレクトリ。
/sys:
カーネルとハードウェアに関する情報が格納。
/tmp (temporary):
一時ファイルが格納されるディレクトリ。
/usr (user):
システムの主要なプログラムやファイルが格納。 通常、システムが実行されている間に変更されないファイルがここに含まれる。
/var (variable):
変化するデータ(ログファイル、キャッシュ、一時的なファイルなど)が格納。
クロスサイトスクリプティング(XSS)とは?
Webサイトを閲覧するだけで個人情報が盗まれる可能性のあるクロスサイトスプリプティング(XSS)について説明する。
クロスサイトスクリプティング(XSS)とは?
Webアプリケーションへのサイバー攻撃の手法の一つでアプリケーションの脆弱性を利用してHTMLに悪質なスクリプトを埋め込む攻撃手法
クロスサイトスクリプティング(XSS)の攻撃の流れ
主な流れは以下を参照。
①攻撃者はWebページにスクリプト付きのリンクを含む内容の罠を仕掛ける
②訪問者が該当のWebページを利用。
③リンクをクリックしてスクリプトが実行されると、別のWebサイトに遷移(クロスする)して悪意のある内容(スクリプト)が実行される。
被害に遭うとどうなるか
個人情報の流出やマルウェア感染などの被害に遭う恐れがある。
対策について
移管先のWebサイトで個人情報などの重要な情報の入力やクリックを安易にしないこと。
スプレッドシートをGoogle App Scriptを使用してAWS S3に上げてみた

はじめに
エクセルライクに使えて、誰でも手軽に無料で利用できるスプレッドシート。
今回そのスプレッドシートをCSVの形式でAWS S3にGoogleアップスクリプトを利用してアップロードする方法を紹介します。
CSV形式で保存しておけばそこからPythonを利用して機械学習のデータとして利用できたりと汎用性が高そうです。
前提と注意事項
※ AWSのアカウントの開設やアカウント開設初期の基本的なセキュリティ設定は全て終えている前提です。
※ AWSのUIは頻繁に変わるので執筆時点(2023/02/11)から変わっている場合があります。
IAMを作成する
AWS マネージメントコンソールから、IAMと検索し、IAMのページにアクセス。左サイドバーの「ユーザー」から「ユーザーを追加」をクリック
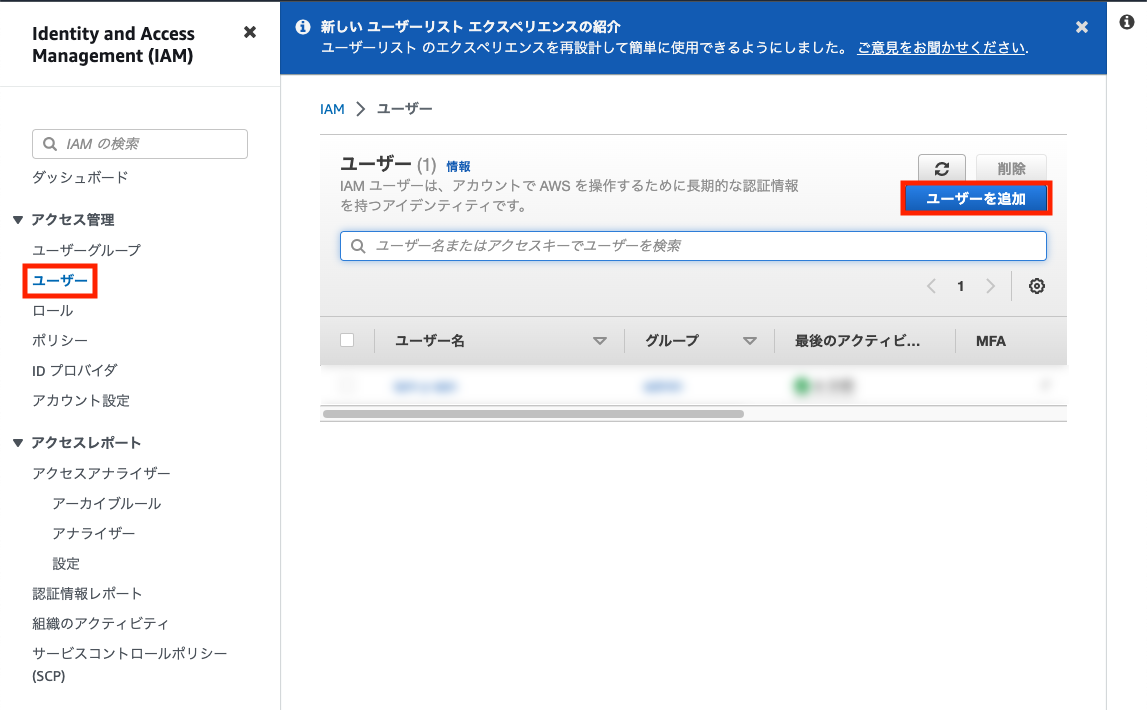
ユーザー名を「S3-access-user」とし、次へをクリック
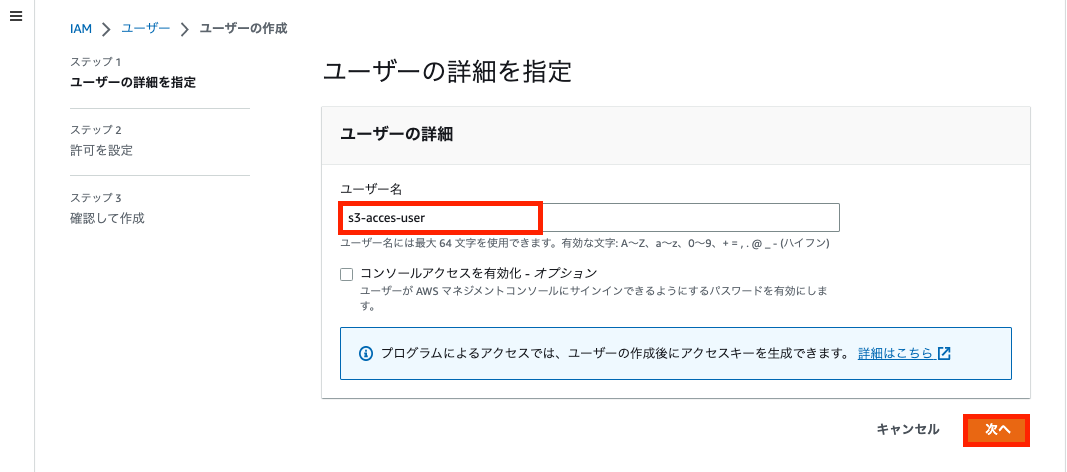
「ポリシーを直接アタッチする」を選択し許可ポリシーの フォームから「S3」と打ち込み「AmazonS3FullAcess」のポリシーを選択。「次へ」をクリック
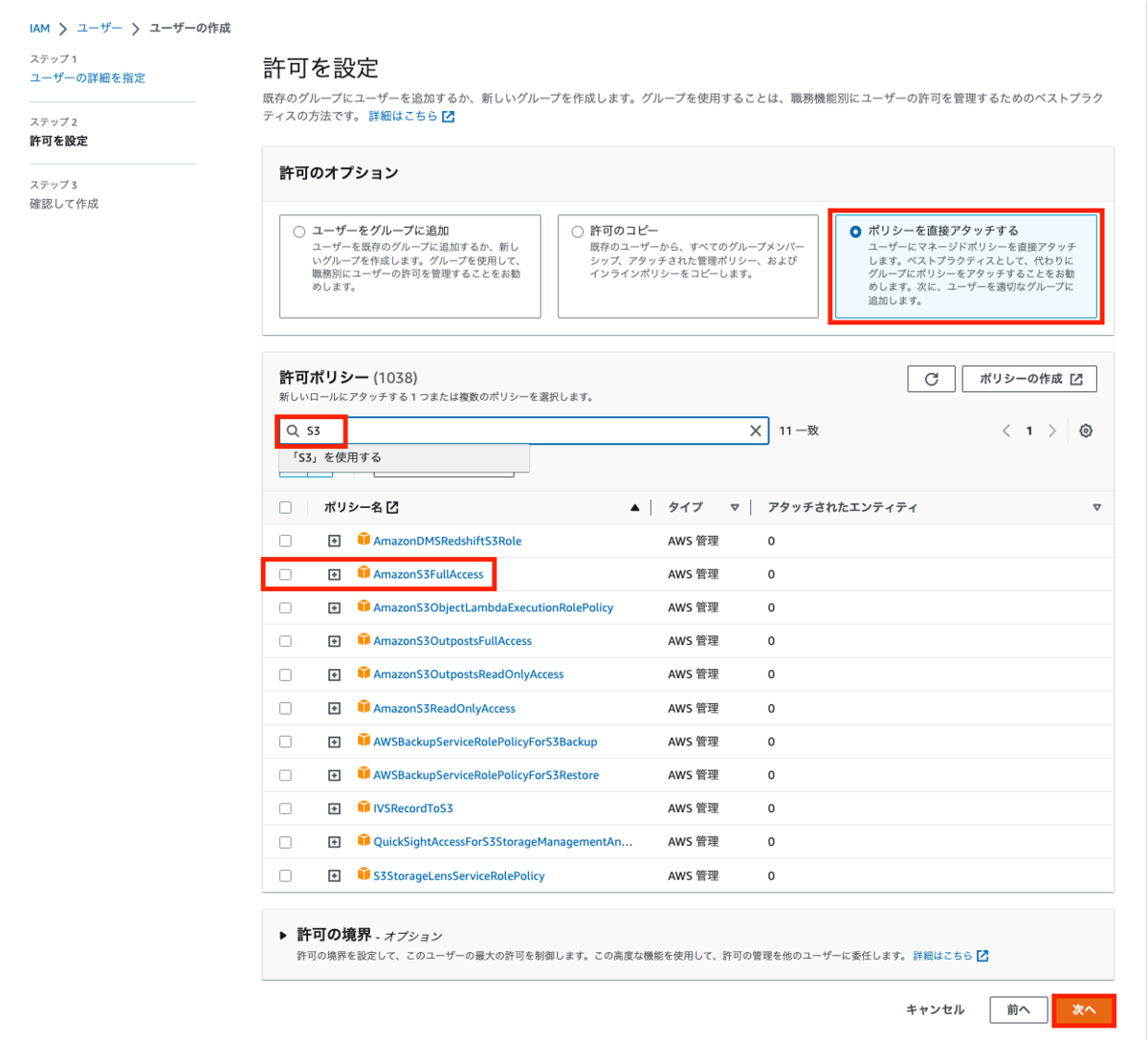
ユーザー名と許可の概要からアタッチしたポリシーを確認し、「ユーザーの作成」を押下

IAMユーザーが作成されていることを確認しユーザー名をクリック

設定項目の「アクセスキーを作成」をクリック
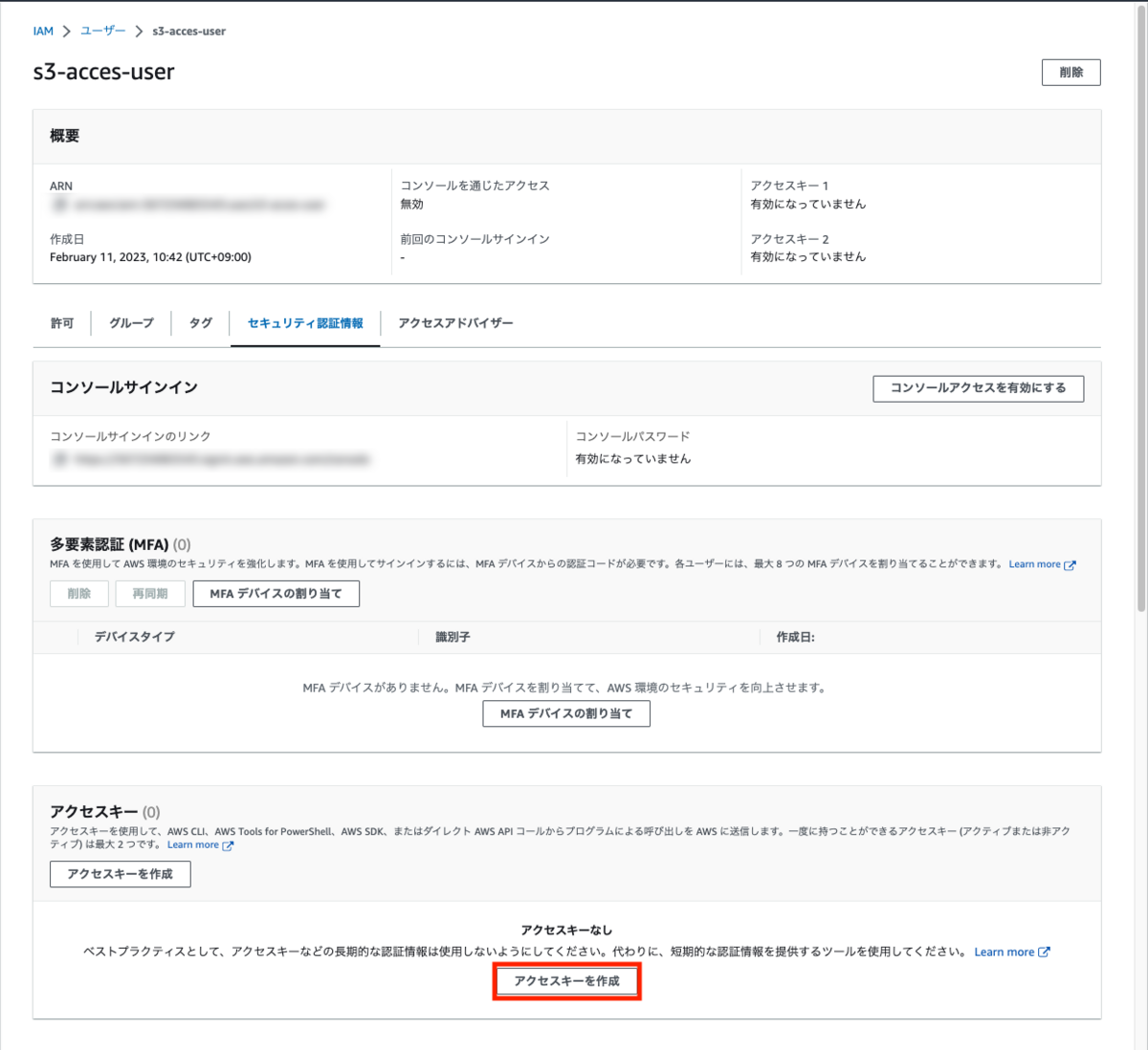
コマンドラインインターフェース(CLI)を選択し確認のラジオボタンにチェックを行い「次へ」をクリック

タグを「GAS」と設定し「アクセスキーを作成」をクリック

必要に応じてCSVファイルをダウンロードしておく。 ここで表示されているアクセスキーとシークレットアクセスキーは控えておく

S3バケットの作成
バケットの作成をクリック

バケット名を「gas-file-access」と入力、AWSリージョンが東京リージョンになっていることを確認する。
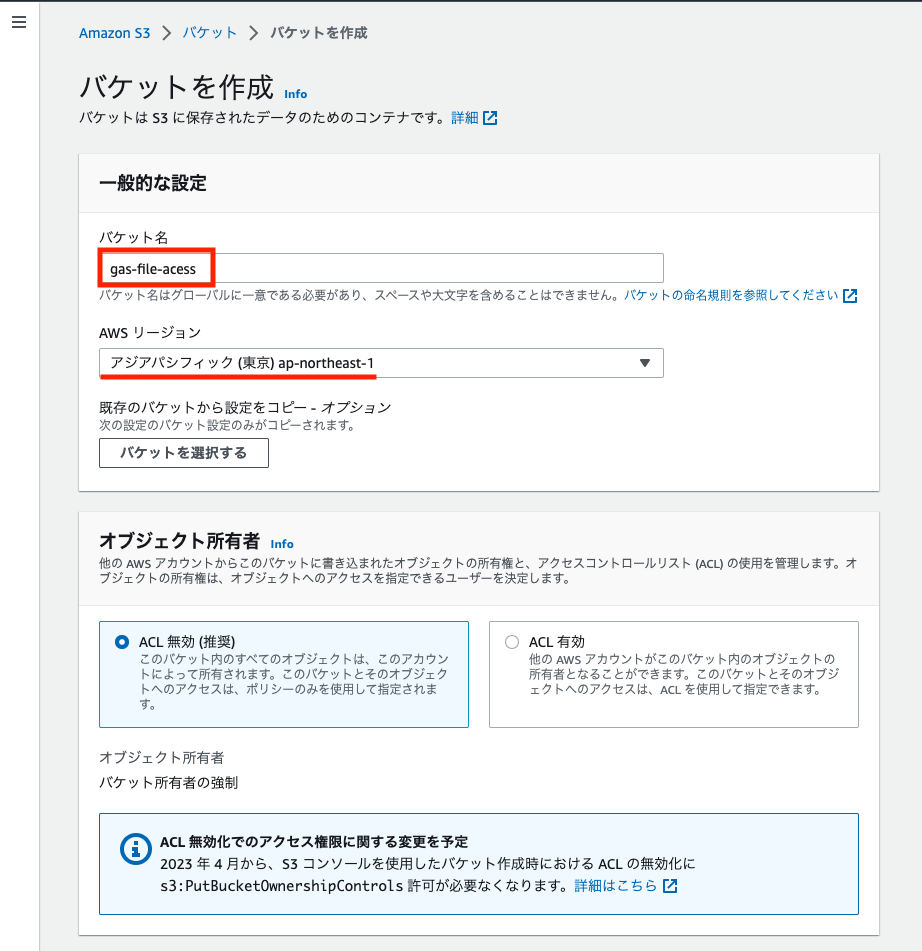
「パブリックアクセスを全てブロック」にチェックが入っていることを確認 またバージョニング機能は今回はいらないので無効にするになっていることを確認
「バケットを作成」をクリック

これでS3バケットが作成される。
スプレッドシートの作成とGoogle App Scriptのコーディング
スプレッドシートを作成し、シート名をprice-listとしておく

拡張機能→Apps Scriptを選択
以下のスクリプトを貼り付ける
const accessKey = "XXXXXXXX"; // アクセスキー(IAM作成で控えたもの) const secretKey = "XXXXXXXX"; // シークレットキー(IAM作成で控えたもの) const bucketName = "gas-file-access"; // S3バケット名 const spreadSheetId ="XXXXXXXX"; //スプレッドシートのID function myFunction() { // ライブラリスクリプトID // 1Qx-smYQLJ2B6ae7Pncbf_8QdFaNm0f-br4pbDg0DXsJ9mZJPdFcIEkw_ // スプレッドシートを取得 var ss = SpreadsheetApp.openById(spreadSheetId); // シートのオブジェクトを取得 var sheet = ss.getSheetByName('price-list'); // データ取得 var data = sheet.getRange('A:C').getValues(); // idがあるデータだけ抽出 var csv = ''; for ( var i = 0; i < data.length; i++ ) { if ( data[i][0] != '' ) { csv += '"' + data[i][0] + '","' + data[i][1] + '","' + data[i][2] + '"' + "\n"; } } // バイナリに変換 csv = Utilities.newBlob( csv ); var s3 = S3.getInstance( accessKey, secretKey ); s3.putObject( 'gas-file-access', 'test-data/price-list.csv', csv, {logRequests:true} ); }
スプレッドシートのIDは以下URL部分の*の部分になる
https://docs.google.com/spreadsheets/d/********/edit#gid=0
ライブラリを追加する
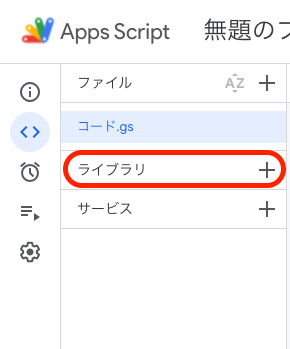
モーダルが表示されたらスクリプトI Dを入力し、検索ボタンを押下
スクリプトID:1Qx-smYQLJ2B6ae7Pncbf_8QdFaNm0f-br4pbDg0DXsJ9mZJPdFcIEkw_

ライブラリS3が確認できたら追加を押下
実行ボタンをクリック

S3バケットにデータが挿入される。

所感
結構簡単に実装できるもんだなぁと感心しました。 一方でGoogle App Scirpt上でアクセスキーとシークレットキーを使用する部分があるので共通で編集するファイルなどには今回の実装は含めない方がいいです。
あくまで個人で利用する場合に限定した方が良さそうですね。
Jupyter Labで作成したNotebookをはてなブログに貼り付ける方法

技術系の記事を書くときソースコードいちいち載せるのめんどくさい
勉強したことを見返したり、インプットしたことをそのままにしておいて知識的な便秘にならないように日々しているわけですがいかんせんソースコードの転記がめんどくさい。
Pythonを書く時にはプログラムの対話型実行環境のJupyter Labを使っているわけですがコレそのまま貼り付けられないのかな?と思ったことが今回の記事のネタの出どころになっております。
結論:Jupyter Labで作成したipynbファイルははてなブログにそのまま貼り付け可能
Githubが提供している「GitHub Gist」を使えばできるみたいです。Githubほどversion管理とかするまでもないソースコードを共有するのに便利なサービスのようです。 知らなかった。 世の中便利になってるなぁ
手順
Jupyter Labで作成したファイルを用意する
GitHub Gistにアクセス gist.github.com
中央のソースコード記入のウィンドウにファイルをドラックアンドドロップ
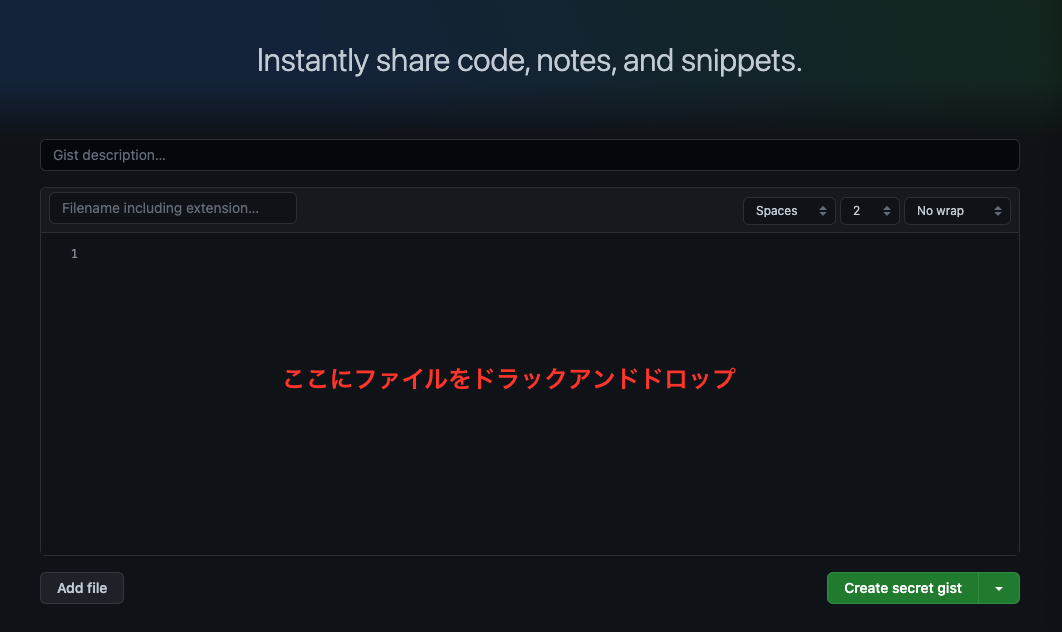
右下のアロー(下三角)ボタンから「create public gist」を選択しボタンを押下

privateで保存をするとはてなブログとの連携ができなくなるので注意 作成内容を確認する
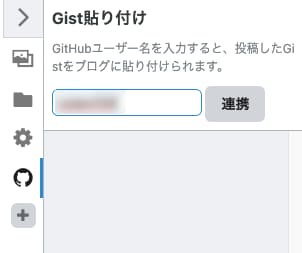
はてなブログに移動し、記事の編集画面の右側にあるサイドバーのプラスボタンをクリック。 Git Gistのラジオボタンをオン(緑)にする。
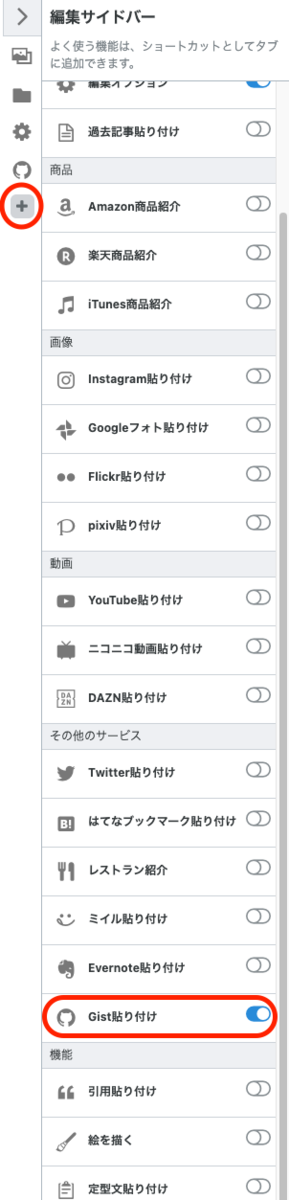
自分のGithub名を入力して連携ボタンを押す
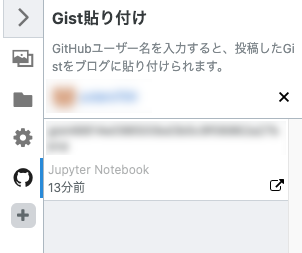
先ほど貼ったNotebookが出てくるので選択すれば貼り付け完了!
おわりに
たまに自分のアカウントを連携してもNotebookが出てこなかったり、「連携が失敗しました」と出る時があるので一旦下書きしてからページをリロードしたり、連携を解除してから再度してみたりと試してみてもらえればと思います。
Go ステートメント編
ステートメント編

if文
基本のif文
package main import "fmt" func main(){ num := 6 // 余剰がなければ"by 2" if num % 2 == 0 { fmt.Println("by 2") }
if else文
package main import "fmt" func main(){ num := 6 // 余剰がなければ"by 2"あれば"else" if num % 2 == 0 { fmt.Println("by 2") } else { fmt.Println("else") }
else if文
pacage main import "fmt" func main() { num := 6 // 2で割って余剰がなければ"by 2" // 3で割って余剰がなければ"by 3" // 余剰があれば"else" if num % 2 == 0 { fmt.Println("by 2") } else if num % 3 == 0 { fmt.Println("by 3") } else { fmt.Println("else") } }
論理演算子
package main import "fmt" func main() { x, y := 11, 12 // 論理積(左辺も右辺もtrueの場合にtrue) if x == 10 && y ==10{ fmt.Println("&&") } // 論理和(左辺か右辺のどちらかがtrueの場合にtrue) if x == 10 || y ==10{ fmt.Println("||") } // 論理否定 if x != 10 { fmt.Println("||") }
if文 関数の呼び出し
// 2で割った際の余剰を判定 func by2(num int) string{ if num % 2 == 0 { return "ok" } else { return "no" } } func main() { // 関数を変数resultに挿入してif文を実行 result := by2(10) if result == "ok" { fmt.Println("great") } // セミコロンを使用してワンライナーで記述も可能 if result2 := by2(10); result2 == "ok"{ fmt.Println("great 2") } }
for文
for文の基本
package main import "fmt" func main(){ // i が10 以上になるまで繰り返す for i := 0; i < 10; i++ { fmt.Println(i) }
continue
package main import "fmt" // continue for i :=0; i < 10; i++ { if i == 3{ fmt.Println("continue") continue } fmt.Println(i) }
break
for i :=0; i < 10; i++ { if i == 3{ fmt.Println("continue") continue } if i > 5 { fmt.Println("break") break } fmt.Println(i) }
for文の別の書き方
sum := 1 for ; sum < 10; { sum += sum fmt.Println(sum) } fmt.Println(sum) }
;(セミコロン)の省略も可能
sum := 1 for sum < 10 { sum += sum fmt.Println(sum) } fmt.Println(sum) }
無限ループ
for {
fmt.Println("hello")
}
switch分
基本的なswich文
package main import "fmt" import "time" func main(){ os := "mac" switch os { case "mac": fmt.Print("Mac!!") case "windows": fmt.Print("Windows!!") default: fmt.Println("Default!!") }
defaultを省略した場合は処理がされないまま終了する
func main() { switch os { case "mac": fmt.Print("Mac!!") case "windows": fmt.Print("Windows!!") } } // >>> Process finished with exit code 0
func getOsName() string{ return "dafdaf" } func main() { switch os := getOsName(); os { case "mac": fmt.Print("Mac!!") case "windows": fmt.Print("Windows!!") default: fmt.Println("Default!!") } } // 外側で変数osを使おうとするとスコープ外でエラーになる fmt.Println(os)
switchのところで条件を書かなくても処理ができる
t := time.Now()
fmt.Println(t.Hour())
switch {
case t.Hour() < 12:
fmt.Println("Morning")
case t.Hour() < 17:
fmt.Println("Afternoon")
}
}
defer
遅延実行
package main import "fmt" func main(){ // defer 遅延実行 main関数の処理が終わってからdeferで定義したものが動く defer fmt.Println("world") fmt.Println("hello") } // >>> hello // >>> world
deferを持っている関数を呼び出した場合はその関数内のdeferが終わってからmain関数となる
func foo() { defer fmt.Println("world foo") fmt.Println("hello foo") } func main(){ foo() defer fmt.Println("world") fmt.Println("hello") } // >>> hello foo // >>> world foo // >>> hello // >>> world
deferが並んだ場合は最後のdferから逆順に実行されてゆく
func main(){ fmt.Println("start") defer fmt.Println("1") defer fmt.Println("2") defer fmt.Println("3") fmt.Println("end") } // >>> start end 3 2 1
そもそものdeferの使いどきはいつなのか?
ファイルを取り扱う際に使用したりすることが比較的多い
*lesson.goがある想定で
func main() { file, _ := os.Open("./lesson.go") defer file.Close() data := make([]byte, 100) // バイト配列の作成 file.Read(data) //バイト配列を挿入 fmt.Println(string(data)) // stringにキャストして出力 }
log
基本的にGOはログ出力において他の言語のように INFO やERROR などを組み込んだ標準ライブラリで提供していないのでもし他言語のようにエラーハンドリングを行いたいのであればサードパーティライブラリを使用する必要がある
package main import ("log" "fmt" "os" "io" ) func loggingSettings(logFile string){ logfile, _ := os.OpenFile(logFile, os.O_RDWR | os.O_CREATE | os.O_APPEND, 0666) multiLogFile := io.MultiWriter(os.Stdout, logfile) log.SetFlags(log.Ldate | log.Ltime | log.Lshortfile) log.SetOutput(multiLogFile) } func main(){ // 基本系 log.Println("logging!") log.Printf("%T, %v", "test", "test")
Fatal
Fatal以降は処理が終了するので後続のコードは実行されない
log.Fatalf("%T, %v", "test", "test") // 以降出力されない log.Fatalln("error!!") // 出力されない fmt.Println("ok!")
// 存在しないファイルを開こうとする
_, err := os.Open("fdfdfdfd")
if err != nil{
log.Fatalln("Exit", err)
}
// >>> Exit open fdfdfdfd: no such file or directory
}
エラーハンドリング
他の言語のようにtry exceptのようにハンドリングする訳ではなく、使用した関数においてerrが返却されるものに対してひとつひとつに対してif文でエラーハンドリングするのがGoの作法としてある
package main import ("log" "os" ) func main(){ file, err := os.Open("./lesson.go") if err != nil { log.Fatalln("Error!") } defer file.Close() data := make([]byte, 100) count, err := file.Read(data) if err != nil{ log.Fatalln("Error") } fmt.Println(count, string(data)) // err 変数が2回目のshort decraretionのinisirazeとなっているが、どれかひとつinisirazeされていればエラーにならない if err = os.Chdir("test"); err != nil{ log.Fatalln("Error") } }
panicとrecover
panicやrecoverを使用することは実はあまり推奨されていない。 エラーハンドリングをきちんとしようという考えからきている
package main import "fmt" func thirdPartyConnectedDB(){ panic("Unable to connect database!") } func save(){ thirdPartyConnectedDB() defer func(){ s := recover() fmt.Println(s) } } func main(){ save() fmt.Println("OK?") } // >>> Unable to connect database ! // >>> thirdPartyConnectedDBメソッドでパニックが起こる
ThirdPartyConnectedDBメソッドでパニックが起こるが、defer 文は panic() 関数が呼ばれるかに関わらず処理される
package main import "fmt" func thirdPartyConnectedDB(){ panic("Unable to connect database!") } func save(){ defer func(){ s := recover() fmt.Println(s) } thirdPartyConnectedDB() } func main(){ save() fmt.Println("OK?") } // >>> Unable to connect database ! // >>> OK?
Go ポインタ編
Go ポインタ編

ポインタ
package main import "fmt" func main(){ var n int = 100 fmt.Println(n) // 100 // &(アンパサンド)はメモリのアドレスを表す fmt.Println(&n) // >>> 0xc00001a040 (変数nのメモリアドレス) // *intでポインタ変数の定義ができ、変数への格納はメモリアドレスを渡す var p *int = &n fmt.Println(p) // >>> 0xc00001a040 // *ポインタ変数 で実体値にアクセスできる(デリファレンスと読んだりもする) fmt.Println(*p) // 100 }
*デリファレンス(dereference)
何かを参照しているものの参照先を見に行くこと。
変数とポインタ変数の挙動の違い
func one(x int){ x = 1 } func main(){ var n int = 100 one(n) // func oneでは書き換えが行われずに100 fmt.Println(n) // >>> 100 }
func two(x *int){ *x = 1 // *xで実体(n)にアクセスし書き換え } func main(){ var n int = 100 two(&n) // 変数nのメモリのアドレスを渡す fmt.Println(n) // >>> 1 }
new
値を入れずにメモリにアドレスだけを確保したい場合はnewを使う
package main import "fmt" func main(){ // メモリにアドレスだけを確保したい場合はnewを使う var p *int = new(int) fmt.Println(p) // >>>0xc0000a0000 // 中身の実体値は0が入っている fmt.Println(p) // >>> 0 // newをしない場合はポインタ型変数の宣言をしてもメモリを確保がされていない var p2 *int fmt.Println(p2) // >>> nil // 中身を確認すると panicでerrorが返却される fmt.Println(*p2) }
struct
package main import "fmt" // capital paburiku // プライベートになる type Vertex struct{ X int Y int } func main() { v := Vertex{X:1, Y:2} fmt.Println(v) // vの中にもアクセスできる fmt.Println(v.X, v.Y) // 中身の書き換え v.X = 100 fmt.Println(v.X, v.Y) type Vertex2 struct{ X int Y int S string }
func main() { v := Vertex{X:1, Y:2} fmt.Println(v) // vの中にもアクセスできる fmt.Println(v.X, v.Y) // 中身の書き換え v.X = 100 fmt.Println(v.X, v.Y) // 指定していなければデフォルトのint 0が挿入される(stringであれば空) v2 := Vertex{X: 1} fmt.Println(v2) // >>> {1 0} // structの中身を指定しない場合は順番通り入れればOK v3 := Vertex2{1, 2, "test"} fmt.Println(v3) // >>> {1 2 test} // 全て指定しなければデフォルトで返却される v4 := Vertex2{} fmt.Println(v4) // >>> {0 0 } fmt.Printf("%T %v\n", v4, v4) // nilにはならない sliceやmapはnilになる var v5 Vertex2 fmt.Printf("%T %v\n", v5, v5) v6 :=new(Vertex2) fmt.Printf("%T %v\n", v6, v6) // pointerが帰ってきている v7 := &Vertex2{} // こっちを使う人の方が多い気がする fmt.Printf("%T %v\n", v7, v7) // pointerが帰ってきている s := []int{} s := []int{} }